Interests
- Multimodal representation learning (text–image–video)
- Evaluation and alignment of vision–language models
- Retrieval-augmented generation and video summarization
- Safety, brand suitability, and content classification
Machine Learning Researcher · Multimodal AI
Based in Seoul, South Korea
I work on vision–language models, large-scale video understanding, and practical MLOps for deploying these systems in real products. I’m especially interested in retrieval-augmented pipelines, representation learning, and evaluation for safety and robustness.
I am a machine learning researcher working on multimodal AI and real-world deployment of vision–language systems. My recent work focuses on video search and summarization, content understanding, and evaluation pipelines that connect research models to production constraints.
Broadly, I enjoy working at the boundary between research ideas and systems that actually ship: designing models and representations, and then building the data, training, and inference infrastructure needed to make them useful in practice.
I am currently organizing my publications, patents, and project notes. A more detailed, paper-style list will appear here soon.
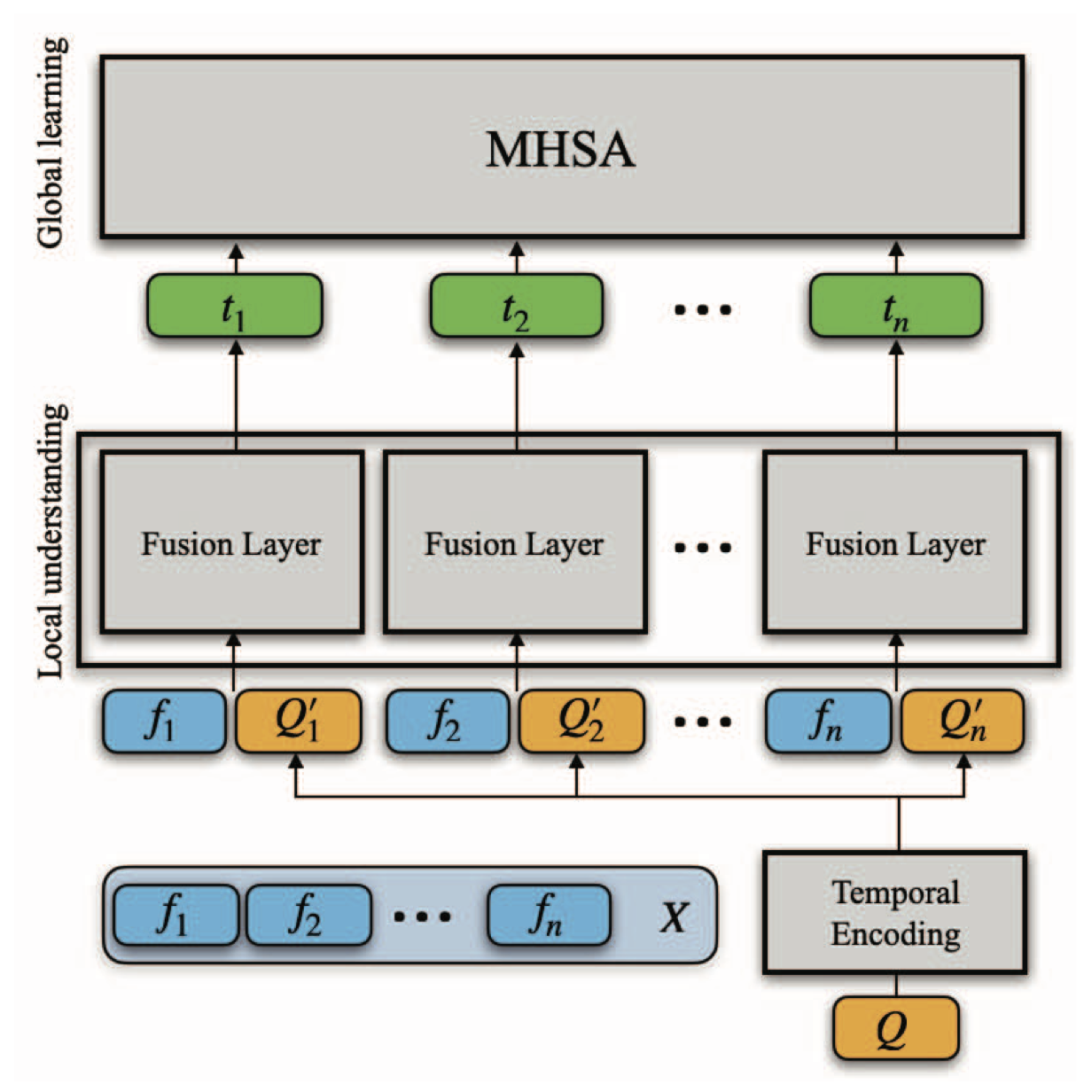
2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2023
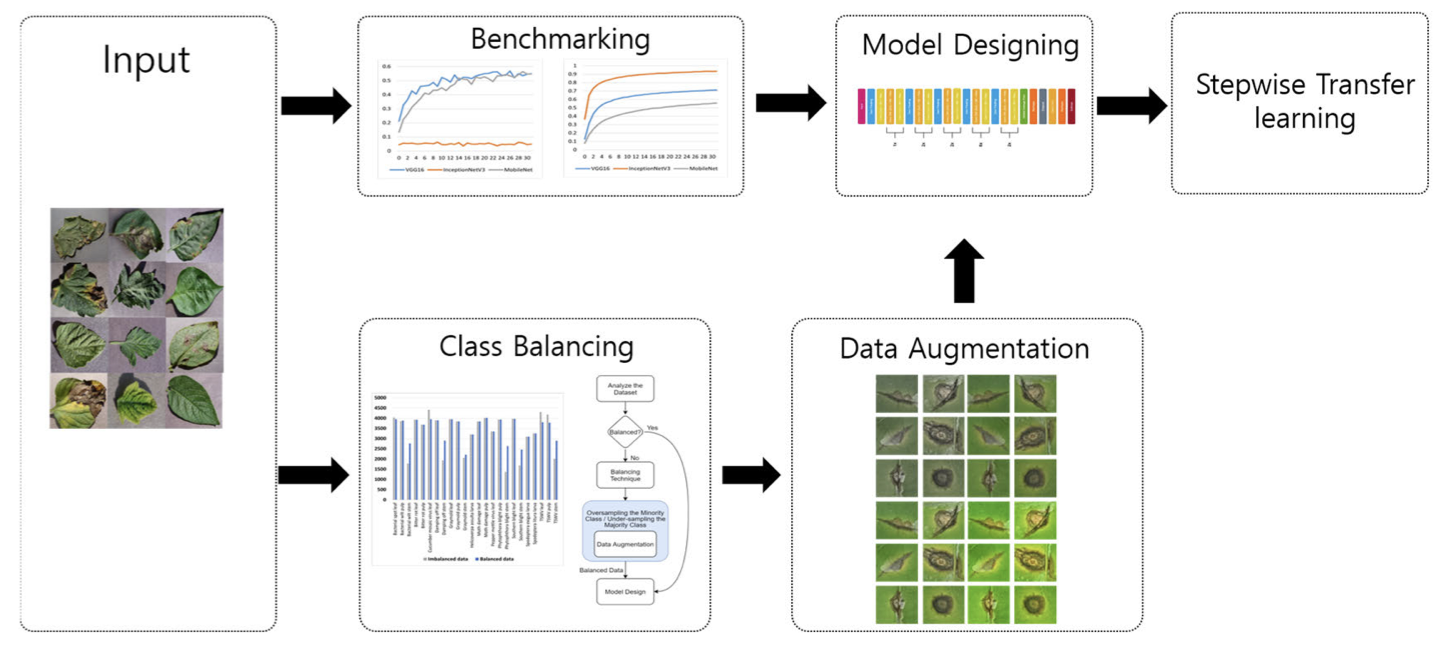
IEEE Access, 9:140565–140580, 2021
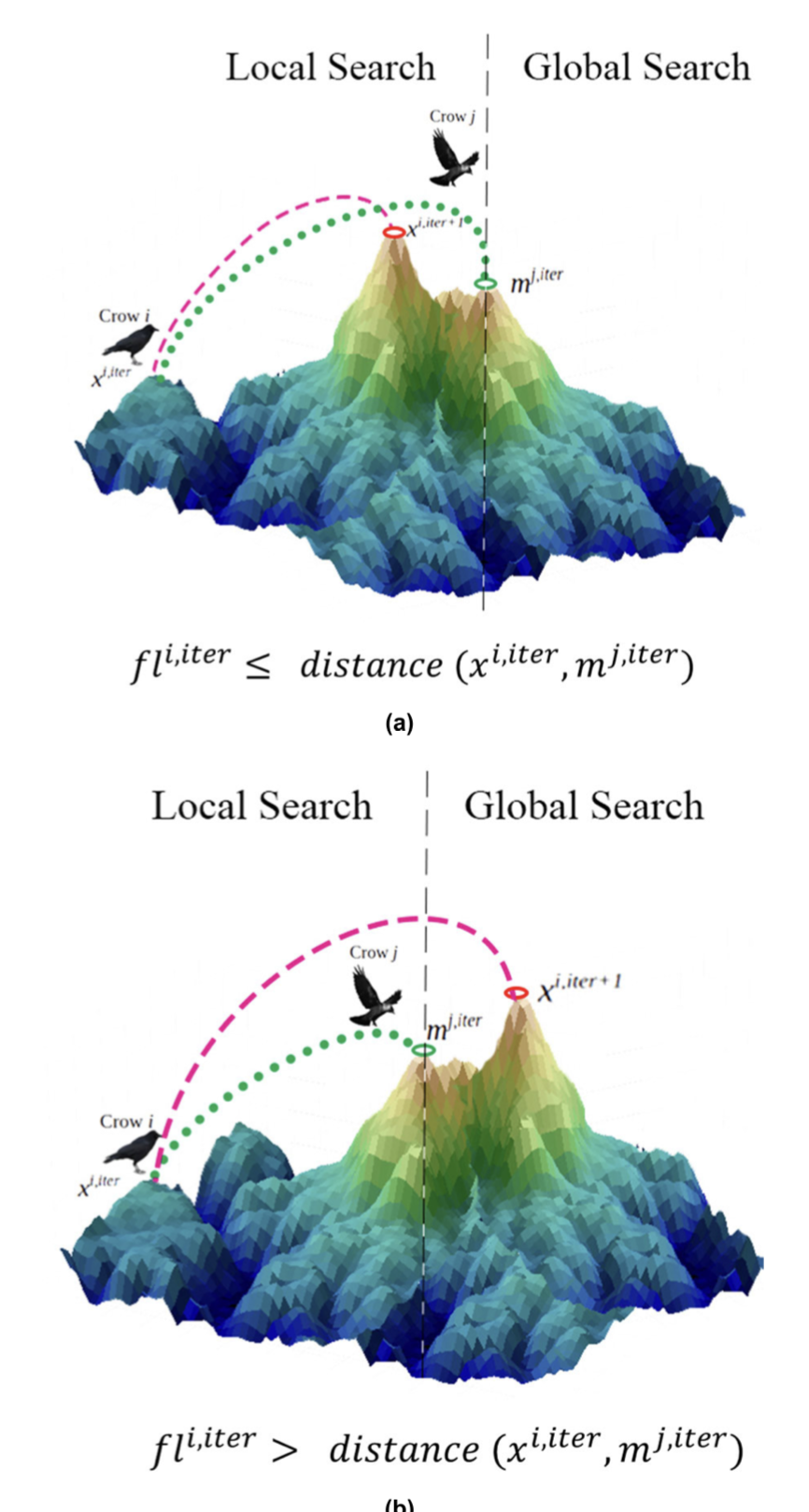
IEEE Access, 8:189891–189912, 2020
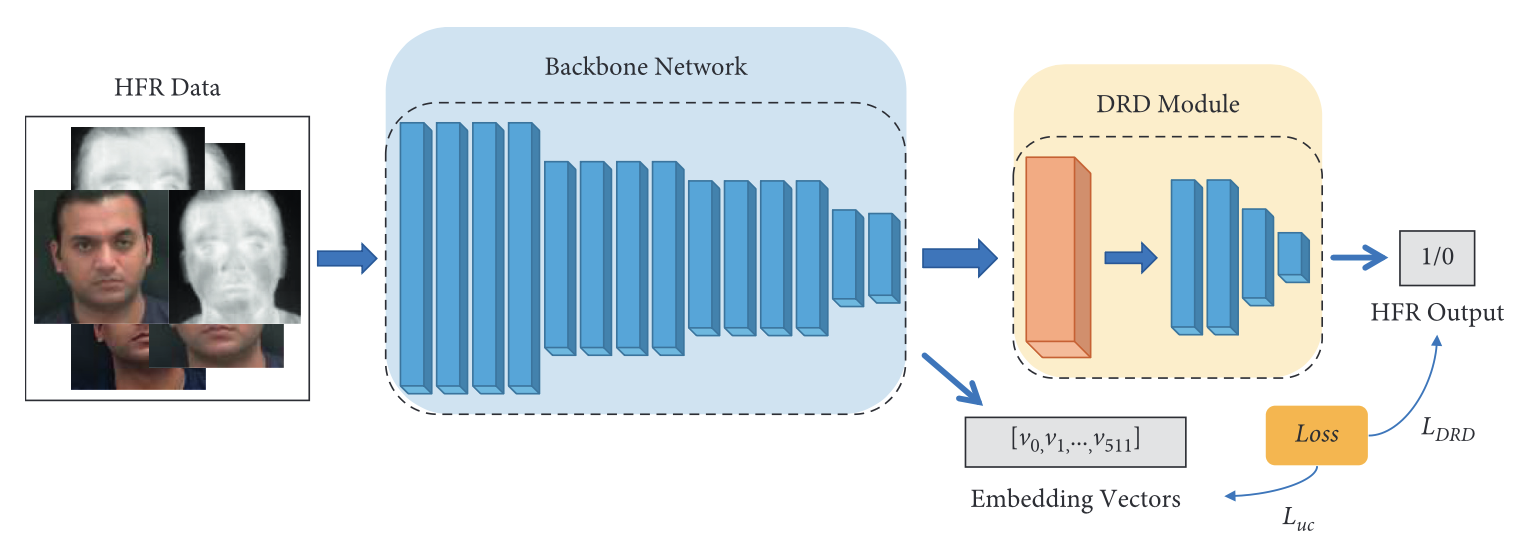
Computational Intelligence and Neuroscience, 2022
Below are a few representative areas I’ve worked on recently. Some are research-oriented; others are closer to production ML engineering.
End-to-end pipeline for semantic video analysis and retrieval using multimodal embeddings, automatic speech recognition, and LLM-based content understanding. Developed novel fusion techniques for combining visual, audio, and textual features at scale.
Fine-tuning and evaluation frameworks for vision-language models in content classification tasks. Developed interpretable multi-label classification systems with emphasis on robustness, fairness, and explainable AI outputs.
AI-powered tools for efficient academic paper analysis, including automated highlighting, semantic note-taking, and LLM-assisted literature review workflows. Designed to accelerate research discovery and knowledge synthesis.
A detailed CV is available on request; this is a compact snapshot of my recent work.
Working on video understanding, multimodal retrieval, and large-scale evaluation frameworks that connect LLMs/VLMs to real production workloads.
Research on model design and training methods with a focus on reducing human effort and deploying practical systems.
I’m open to conversations about research collaboration, postdoctoral opportunities, applied ML projects, and practical deployment of multimodal systems.
Email: ahmadmobeen24@gmail.com